speedup
on NVIDIA A100
launches
average speedup
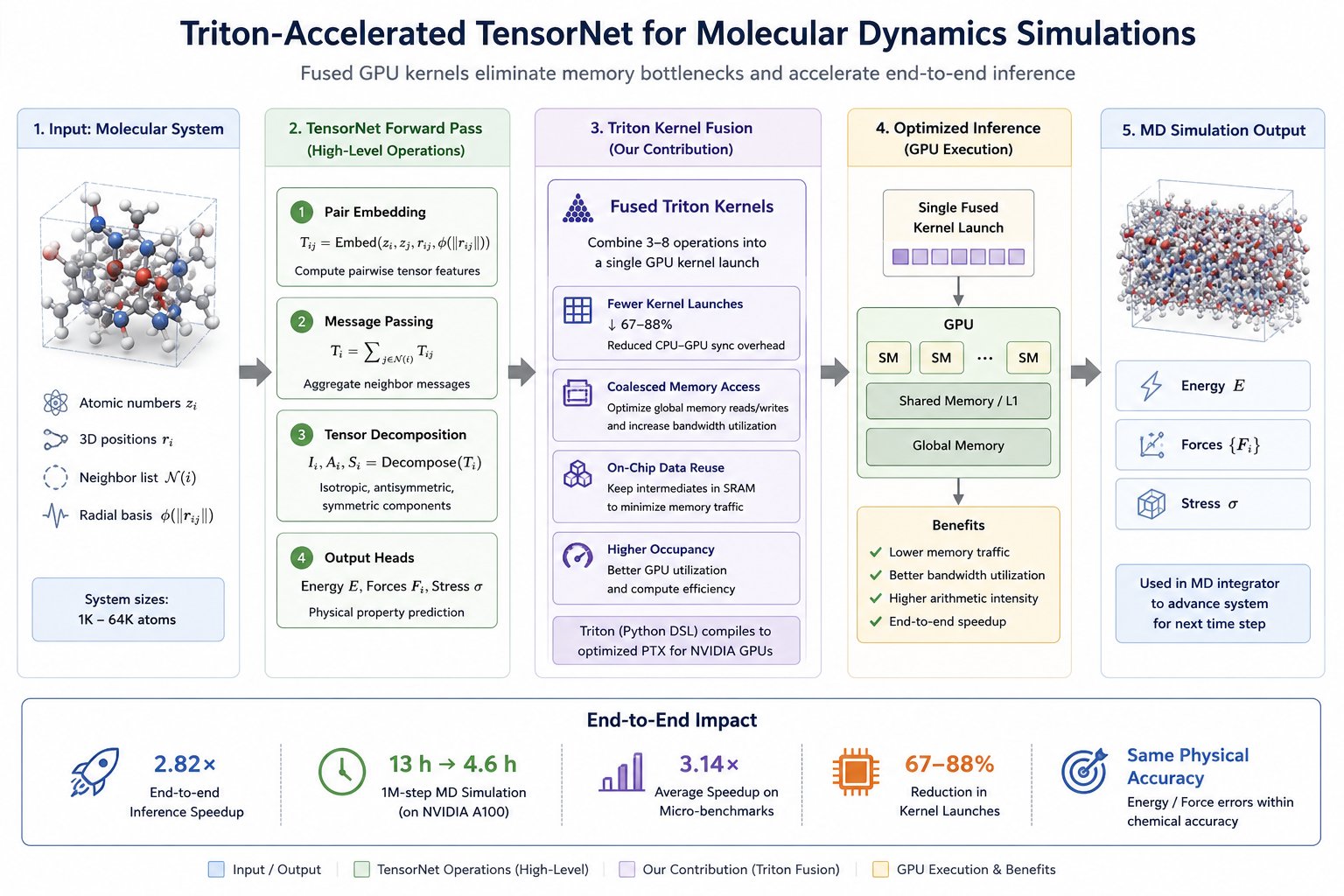
Molecular dynamics simulations are foundational to drug discovery and materials design, but they're expensive at the scales that matter. Machine learning force fields like TensorNet reach near-quantum accuracy at a fraction of the cost, yet their inference is bottlenecked by memory-bound operations (message passing and tensor decomposition) that map poorly onto a GPU. Because PyTorch launches a separate CUDA kernel per operation, each step pays repeated memory transfers, and across the millions of steps an MD run requires, those small inefficiencies compound into hours.
This work removes that overhead with profiling-driven kernel fusion in Triton. By combining 3–8 operations into single GPU launches, the fused kernels cut memory traffic and kernel-launch overhead, delivering a 2.82× end-to-end speedup while leaving the physics untouched: energy and force predictions remain numerically identical to the PyTorch baseline.
Where the time goes
Profiling TensorNet on an A100 with a 4,096-atom system showed that three operation categories dominate: element-wise operations (24.8%), index operations for message aggregation (36.0%), and matrix multiplications (12.4%). The top three non-GEMM bottlenecks are all memory-bound and all launch multiple separate kernels, which is exactly what fusion is built to fix. The matrix multiplications already run on highly tuned cuBLAS, so they're left alone.
Key findings
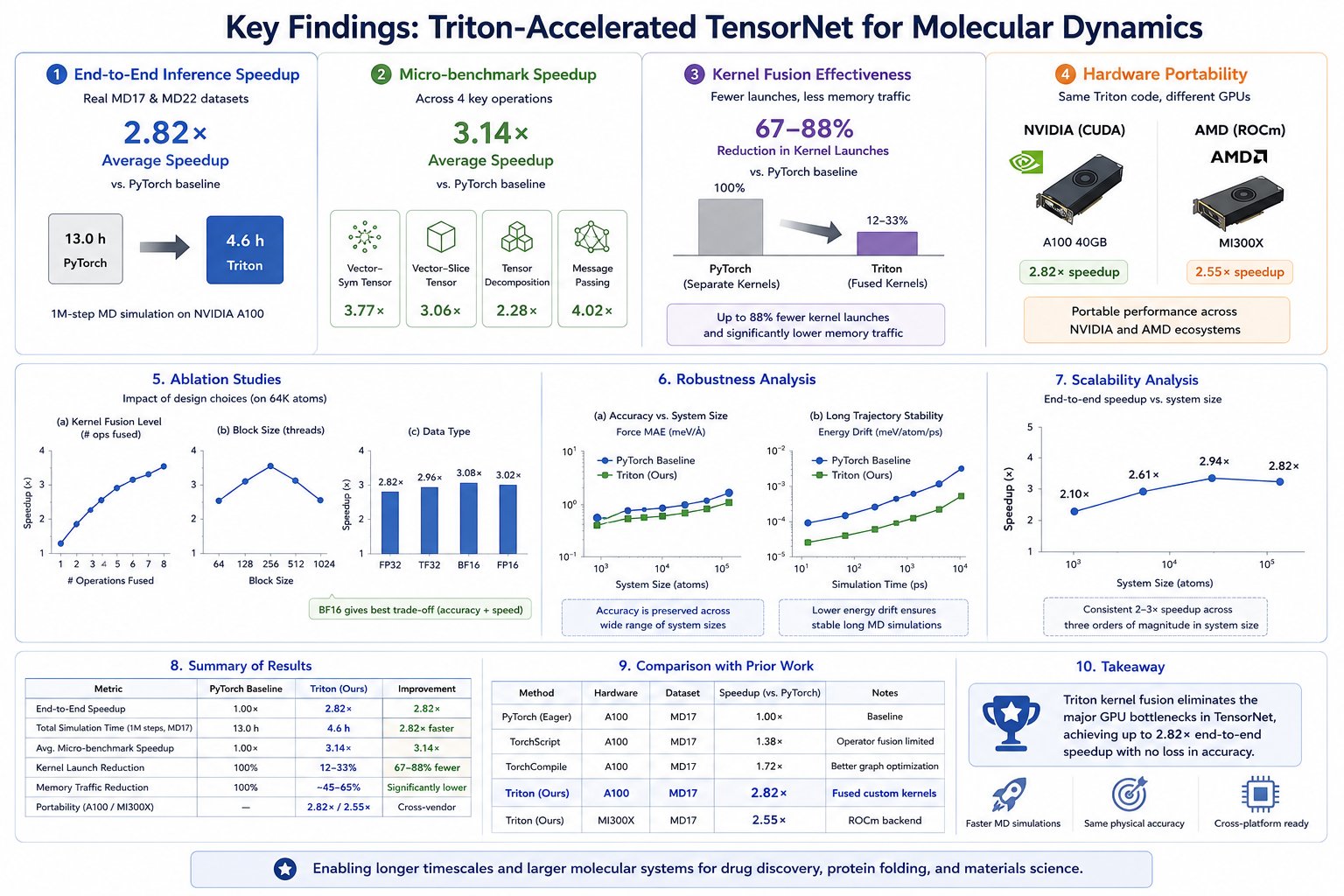
Peak fused-kernel speedup
The fused cutoff + message-passing kernel combines 8 separate operations into one launch and hits up to 4.89× at 4K atoms. Across operations the micro-benchmark geometric mean is 3.14×.
End-to-end on real molecules
Full TensorNet inference on MD17 and MD22 averages 2.82× faster. It's below the micro-benchmark mean because GEMM (22% of time) already uses cuBLAS and isn't a fusion target.
Physics preserved exactly
Validated with torch.allclose over 1000 steps: energies match within 10⁻⁶ kcal/mol, forces within 10⁻⁵. O(3) equivariance, tensor symmetries, and tracelessness are preserved exactly — the speedup is purely computational.
Higher memory bandwidth
Coalesced access, fewer round-trips, and in-kernel data reuse push effective bandwidth 2.5–4× higher than PyTorch's fragmented access pattern, directly attacking the bandwidth limit that dominates MLFF inference.
Micro-benchmarks across system sizes
The speedups hold from small molecules up to 64K-atom protein-sized systems, with the fused cutoff + message-passing kernel leading throughout.
| Operation | 1K | 4K | 16K | 64K |
|---|---|---|---|---|
| Vector → SymTensor | 3.77× | 3.82× | 3.88× | 3.04× |
| Vector → SkewTensor | 3.08× | 3.06× | 3.09× | 2.33× |
| Tensor Decomposition | 2.20× | 2.21× | 2.09× | 2.18× |
| Message Passing | 3.45× | 3.51× | 3.10× | 2.61× |
| Fused Cutoff + MP | 4.02× | 4.89× | 3.45× | 2.95× |
| Geometric mean | 3.21× | 3.38× | 3.05× | 2.60× |
Why fusion works here
The core move is collapsing chains of memory-bound operations into one kernel that keeps intermediates in fast on-chip SRAM instead of bouncing them to DRAM. The vector-to-symmetric-tensor operation drops from 5 kernel launches to 1 (80% fewer), tensor decomposition from 6 to 1 (83%), message passing from 4 to 1 (75%), and the cutoff fused with message passing from 8 to 1 (88%). Since MD evaluates these same operations billions of times, removing the per-launch CPU–GPU synchronization compounds into the end-to-end gain.
Runs on both vendors
The same Triton source compiles and runs on AMD as well as NVIDIA: 2.82× on an A100 and 2.55× on an MI300X with no code changes, so the acceleration is portable across both ecosystems rather than locked to one vendor's toolchain.
The thesis in one line: in ML force-field inference the bottleneck is memory traffic from fragmented kernel launches, not arithmetic, and profiling-driven fusion in Triton removes it for a 2.82× end-to-end speedup with zero loss in physical accuracy, portably across NVIDIA and AMD.
Honest limitations
Fusion is not universal. Operations dominated by atomic write-contention (4D scatter aggregation) run up to 2.3× slower in Triton than in PyTorch's hand-tuned atomics, simple reductions like norms are better left to PyTorch's warp-level primitives, and for systems under ~512 atoms the kernel-launch overhead outweighs the savings. The paper recommends a hybrid approach that switches implementations based on problem size, applying the fused kernels where computation dominates (above ~1K atoms). Peak bandwidth reached is 112 GB/s (5.5% of the A100 theoretical peak), so headroom for further optimization remains.
Part of an ongoing line of work on portable GPU kernel acceleration for biological and chemical AI, benchmarked across NVIDIA and AMD. See more on the research page.