vs. Jellyfish
co-designed
operations, targeted
NVIDIA + AMD
Hardware-algorithm co-design is becoming critical for computational molecular biology, because modern workloads increasingly stress memory bandwidth, parallel execution, and heterogeneous hardware. Despite rapid progress in protein and genomic foundation models, practical performance is held back by inefficient GPU execution: profiling shows 60–80% of runtime is dominated by memory-bound operations, fragmented kernel launches, and repeated device memory transfers, and hardware utilization only gets worse as sequence lengths and batch sizes grow.
This work delivers hardware-aware GPU optimizations in OpenAI Triton where each model is independently optimized with custom fused kernels tailored to its architecture. Multiple PyTorch operations are fused into single kernels to improve memory reuse and cut launch overhead, and the same kernels run unmodified on both NVIDIA and AMD GPUs while preserving numerical correctness within machine precision. These are designed as per-model drop-in replacements, not a single monolithic framework.
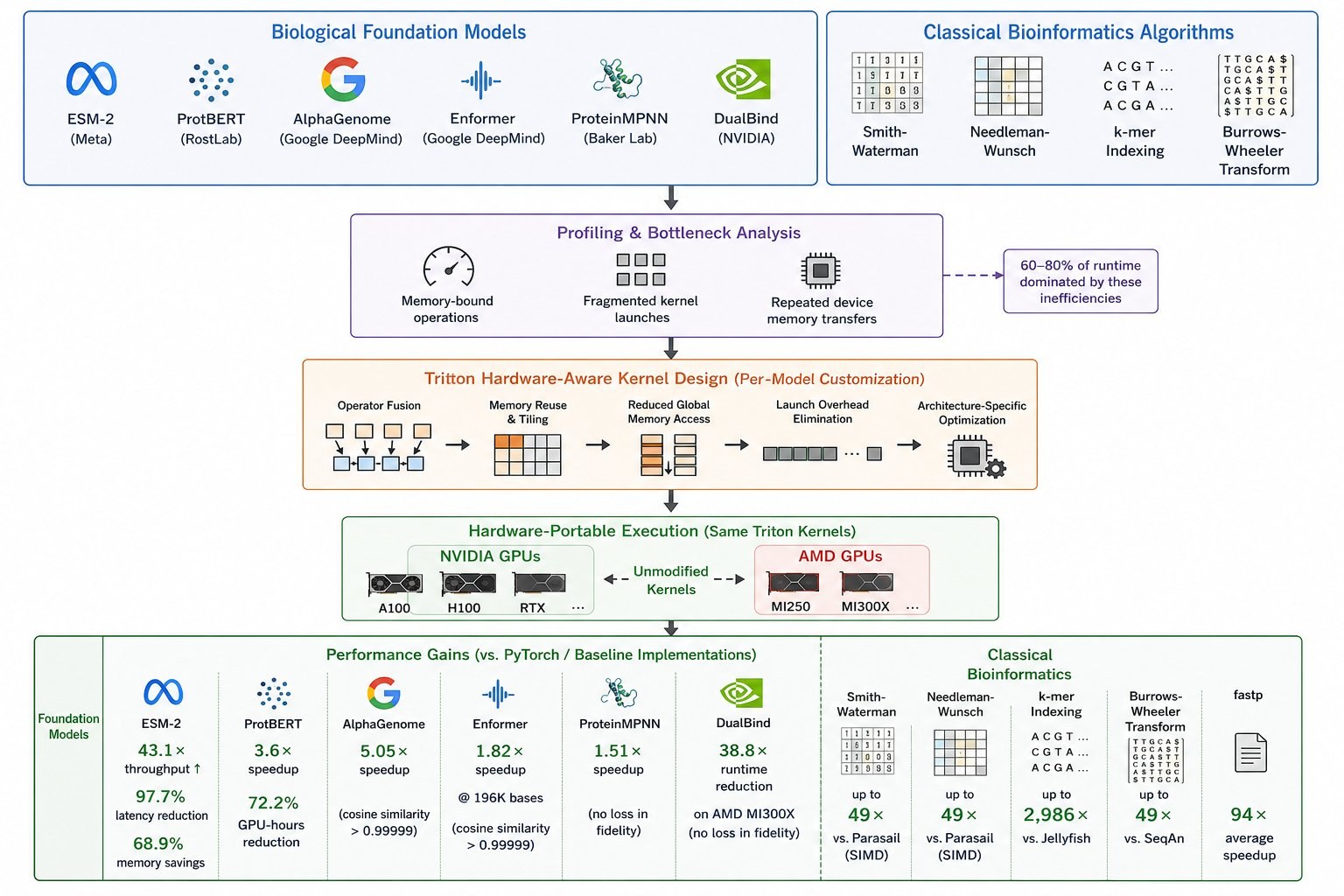
Foundation model results
Protein and genomic foundation models from Meta, Google DeepMind, RostLab, Baker Lab, and NVIDIA are the key beneficiaries, each accelerated with no loss in fidelity.
Meta ESM-2
43.1× throughput improvement, 97.7% latency reduction, and up to 68.9% memory savings over Hugging Face baselines.
DeepMind genomic models
AlphaGenome accelerated 5.05×; the Enformer PyTorch port up to 1.82× on 196K-base inputs, with cosine similarity preserved above 0.99999.
RostLab ProtBERT
3.6× average speedup with identical predictions and a 72.2% reduction in GPU-hours.
NVIDIA DualBind & Baker Lab ProteinMPNN
38.8× end-to-end runtime reduction for DualBind on AMD MI300X, plus a 1.51× speedup for ProteinMPNN, both with no loss in fidelity.
Classical bioinformatics results
Beyond foundation models, the same per-kernel approach accelerates classical algorithms against their established baselines, demonstrating that the method generalizes well past neural networks.
| Algorithm | Speedup | Baseline |
|---|---|---|
| k-mer indexing | up to 2,986× | vs. Jellyfish |
| fastp (preprocessing) | 94× average | vs. fastp |
| Smith-Waterman | up to 49× | vs. Parasail (SIMD) |
| Needleman-Wunsch | up to 49× | vs. Parasail (SIMD) |
| Burrows-Wheeler Transform | up to 49× | vs. SeqAn |
Portable by construction
Every kernel compiles and runs unmodified across NVIDIA and AMD GPUs (A100, H100, RTX on one side; MI250, MI300X on the other). Because the gains come from eliminating memory round-trips rather than vendor-specific intrinsics, performance portability holds without source-level changes, and numerical correctness is preserved within machine precision on both backends.
The thesis in one line: domain-specific GPU kernel design, applied per model and per algorithm, significantly accelerates both modern foundation models and classical bioinformatics workloads on heterogeneous hardware, up to 2,986× and portably across NVIDIA and AMD.
Part of an ongoing line of work on portable GPU kernel acceleration for biological and medical AI, benchmarked across NVIDIA H100 and AMD MI300X. See more on the research page.