dense compute
from one bug fix
measured
no per-vendor forks
AI inference infrastructure is tuned for one workload shape: dense, large-batch, NVIDIA-resident transformer decoding for LLMs. Biological foundation models don't fit that shape. They run at small batch sizes over short alphabets (4–20 tokens, not 100K+), attend over 100K+ token sequences, mix transformer blocks with geometric ops, and increasingly deploy on whatever GPU is available, including AMD MI300X for its 192GB of unified HBM3.
This is a measurement study, framed as an infrastructure paper rather than an ML one. Six widely used biological models (ESM-2, ProtBERT, ProteinMPNN, AlphaGenome, Enformer, DualBind) are benchmarked on three GPUs across two vendors (NVIDIA L4, H100; AMD MI300X). The finding: 60–80% of reference-implementation runtime is spent outside dense compute, and a single Triton kernel source tree closes most of the gap on both vendors with no per-vendor forks.
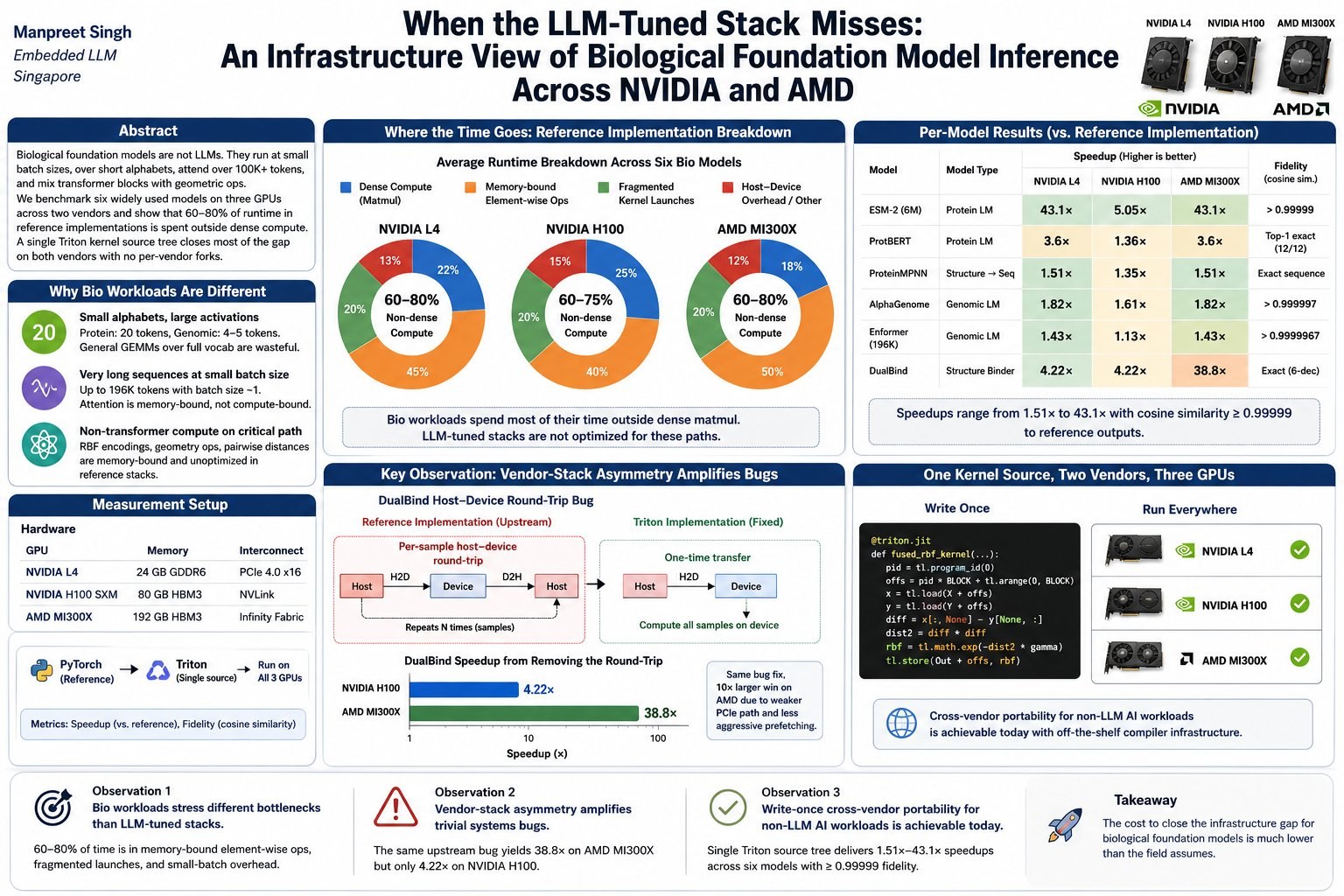
Where the time actually goes
Profiling the reference PyTorch implementations exposes a consistent pattern: across all three GPUs, 60–80% of runtime sits outside dense matmul, in memory-bound element-wise ops, fragmented kernel launches, and small-batch overhead. Vendor LLM kernels don't target these paths, because LLM serving amortizes them over much larger batches and longer decode loops. Three workload properties explain why bio inference lands here: short alphabets make general-vocabulary GEMMs wasteful, very long sequences at batch size one make attention memory-bound rather than compute-bound, and non-transformer geometry (RBF encodings, virtual-Cβ, pairwise distances) shows up as long sequences of small launches with no vendor-library equivalent.
The three observations
Different bottlenecks than LLMs
Bio workloads stress memory-bound element-wise ops, fragmented launches, and small-batch overhead, not the dense matmul path vendor libraries are tuned for. The LLM-tuned stack leaves these paths alone.
Vendor asymmetry amplifies bugs
The biggest win isn't kernel engineering. Removing a per-sample host–device round-trip in upstream DualBind yields 38.8× on MI300X but only 4.2× on H100, because NVIDIA's PCIe path and prefetcher hide the bad code AMD exposes.
Write-once portability, today
A single Triton source tree runs unmodified on L4, H100, and MI300X across all six models, with speedups of 1.51×–43.1× and cosine similarity ≥ 0.99999 to baseline outputs.
Parity is closer than it looks
A fused, GPU-resident kernel masks the latent systems bugs on both vendors and brings NVIDIA and AMD within ~1.4× of each other in absolute throughput, far closer than reference-implementation numbers suggest.
Per-model results
Speedups over the reference PyTorch implementation on the listed GPU, gated by a strict fidelity requirement: cosine similarity ≥ 0.99999, exact-match top-1 predictions, or zero numerical difference to 6 decimal places.
| Model | Hardware | Speedup | Fidelity |
|---|---|---|---|
| ESM-2 (8M) | NVIDIA L4 | 43.1× | cos. > 0.99999 |
| DualBind | AMD MI300X | 38.8× | exact (6-dec) |
| AlphaGenome | NVIDIA H100 | 5.05× | cos. 0.99999997 |
| DualBind | NVIDIA H100 | 4.22× | exact (6-dec) |
| ProtBERT | AMD MI300X | 3.6× | top-1 exact (12/12) |
| Enformer (196K) | NVIDIA H100 | 1.82× | cos. 0.99999825 |
| Enformer (196K) | AMD MI300X | 1.43× | cos. 0.99999967 |
| ProteinMPNN | NVIDIA L4 | 1.51× | exact sequence |
The DualBind lesson
The 38.8× DualBind result is the most important one, and the easiest to misread. The kernel files are identical between vendors. During profiling the upstream DualBind reference turned out not to be GPU-resident end-to-end: it did a per-sample host–device round-trip between the transformer pass and the binding-energy computation. On H100 the PCIe controller, unified-memory prefetcher, and CUDA runtime mask most of that cost. On MI300X the round-trip is exposed, and 800 samples take 41.3s instead of 1.06s. The lesson isn't that AMD is slower, it's that the same upstream code can differ by an order of magnitude across vendors not because the hardware differs by 10×, but because the host–device path differs by 10× in how forgivingly it hides bad code. Bio reference implementations are overwhelmingly developed on NVIDIA; deployed on AMD, latent systems bugs become first-order.
Portability, measured cleanly
The Enformer pair is the cleanest portability evidence: the same Triton source files run on H100 and MI300X at the full 196K-base sequence length, 25 trials each, no ifdefs and no per-vendor tiles. The speedup asymmetry (1.82× vs 1.43×) is a property of the baseline, not the kernel: H100 is slower in absolute terms but had less unfused overhead to remove. This is what write-once cross-vendor performance looks like on a non-LLM AI workload today, not identical speedups, but the same kernel running with measurable wins on both vendors.
The thesis in one line: today's AI infrastructure has a workload shape it wasn't built for; the gap on biological models is large (orders of magnitude in the worst case), vendor-stack asymmetry turns trivial bugs into order-of-magnitude regressions, and the cost to close it with off-the-shelf compiler infrastructure is much lower than the field assumes.
Honest limitations
The six-model selection is biased toward transformer-derived architectures; iterative structure-prediction models (AlphaFold, ESMFold) and diffusion-based designers are absent and likely have different bottleneck profiles. The study benchmarks single-GPU inference only, so multi-GPU sharding and tensor parallelism (which dominate production bio pipelines at scale) are out of scope, and training-time portability across vendors remains open.
Part of an ongoing line of work on portable GPU kernel acceleration for biological and medical AI, benchmarked across NVIDIA H100 and AMD MI300X. See more on the research page.