805ms → 23ms
vs. compiled PyTorch
95% CI excludes zero
single GPU
Real-time ICU early-warning systems need to update at the bedside fast enough to matter, with a practical budget under 50ms per inference. The obstacle turns out not to be the neural network. ICU vital-sign streams are irregularly sampled with 30%+ missing values, and the preprocessing needed to handle that (neighbor search plus interpolation) collapses into sequential GPU work that eats over 85% of total wall-clock time. Even a fast model is clinically unusable behind that bottleneck.
This work removes the bottleneck by co-designing preprocessing and inference. A single fused GPU kernel performs time-aware interpolation of the irregular series and feeds a state-space model in one launch, eliminating the intermediate memory traffic and Python-level overhead that dominated latency. The same kernel source runs on both NVIDIA and AMD hardware without changes.
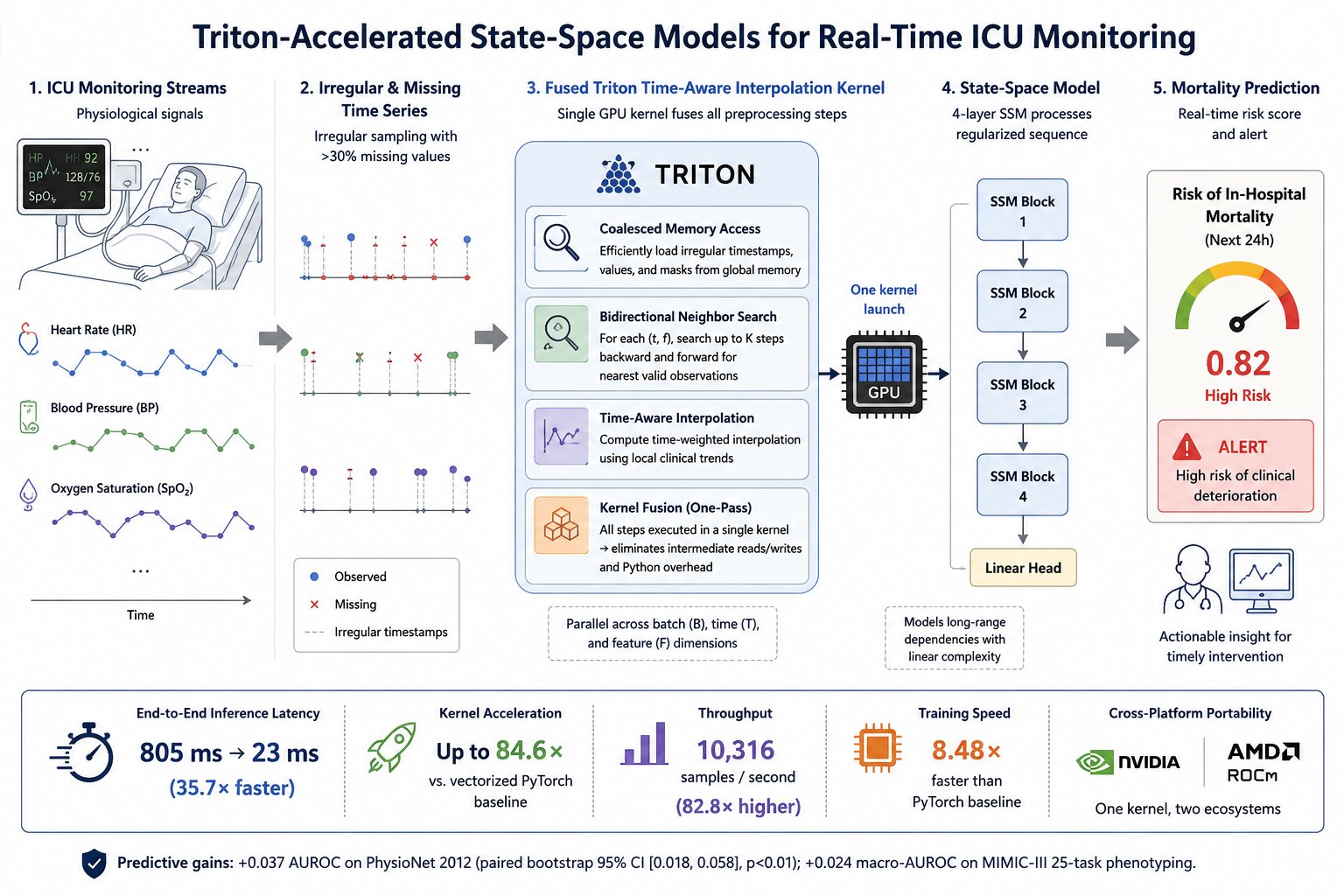
The core idea
For each missing value, the kernel locates the nearest valid observations within a bounded window of K=10 timesteps and computes a time-weighted interpolation, so each output depends only on a local temporal window and the whole operation is fully parallel. The interpolation is fused into one Triton kernel that launches one thread block per (batch, time, feature-tile) combination, exposing parallelism across all three dimensions. Each block does a coalesced load of a 128-feature tile, a bidirectional search with early-exit flags, the time-delta weighting, and a coalesced store, with no intermediate trips back to global memory.
Key findings
Kernel-level acceleration
The fused kernel runs in 0.02–0.05ms across sequence lengths while the optimized PyTorch baseline scales linearly upward. Speedup grows with sequence length, with numerical outputs matching to within 5×10⁻⁷.
Meets the bedside target
End-to-end latency drops from 805ms to 23ms at batch 32, comfortably under the 50ms real-time budget. p99 tail latency stays at 44.6ms, where the PyTorch baseline violates 50ms on 100% of calls.
Significant AUROC gain
On PhysioNet 2012 across 5 seeds, the Triton SSM beats GRU-D by +0.037 AUROC (paired bootstrap 95% CI [0.018, 0.058], Wilcoxon p=0.008) and +0.087 AUPRC, using 2.4× fewer parameters.
BF16 is free speed
Switching FP32 → BF16 yields a further 1.6× kernel speedup with AUROC unchanged within seed variance. FP16 matches the speed but shows sporadic NaNs on extreme outliers, so BF16 is the recommended precision.
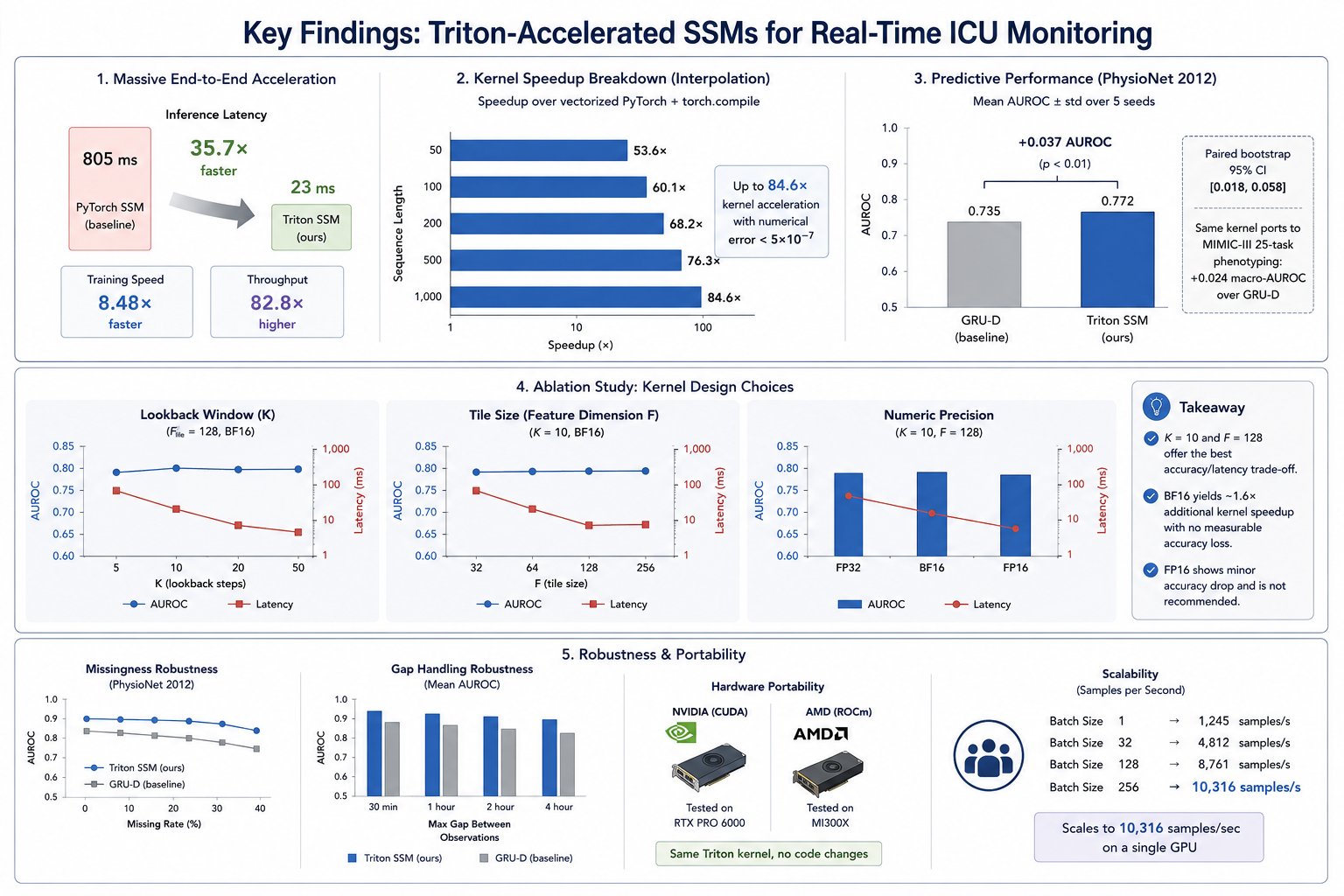
Head-to-head on PhysioNet 2012
Under a matched parameter budget and averaged over 5 seeds, the state-space model is both faster and more accurate than the GRU-D baseline, while using fewer parameters.
| Metric | Triton SSM | GRU-D | Δ vs. GRU-D |
|---|---|---|---|
| Parameters | 827,266 | 2,012,865 | 2.4× fewer |
| Training time | 149.9s | 343.3s | 2.29× faster |
| AUROC | 0.659 ± 0.011 | 0.622 ± 0.014 | +0.037 (p=0.008) |
| AUPRC | 0.328 ± 0.014 | 0.241 ± 0.018 | +0.087 (p=0.012) |
| Latency | 34.1ms | 117.5ms | 3.44× lower |
It generalizes beyond mortality
The same fused kernel transfers to the MIMIC-III 25-task phenotyping benchmark without modification, with only the input feature dimension and SSM head re-instantiated. It delivers +0.024 macro-AUROC over GRU-D (95% CI [0.014, 0.036], p<0.01) and cuts per-stay inference latency from 142ms to 27ms (5.3× lower).
Why it's fast
A roofline analysis confirms the kernel is bandwidth-bound (arithmetic intensity 0.30 FLOP/byte) and operates near the hardware ceiling, reaching 1,344 GB/s of effective HBM bandwidth (75% of peak) versus 143 GB/s (8%) for the PyTorch baseline. The remaining gap to the roofline comes from control-flow divergence in the bidirectional neighbor search and partial write masking at irregular sampling boundaries.
Runs on both vendors
The identical Triton source compiles and runs on AMD MI300X with under 8% latency overhead versus NVIDIA, with no source-level changes. On MI300X the much larger HBM3 capacity (192 GB) permits batch sizes up to 4,096 without spilling, and the higher peak bandwidth partially offsets the wavefront divergence in neighbor search.
The thesis in one line: in clinical time-series pipelines the preprocessing, not the model architecture, is the dominant cost, and fusing it into a single GPU kernel turns an order-of-magnitude latency problem into a solved one, on commodity hardware from either vendor.
Honest limitations
The 0.66 AUROC on PhysioNet 2012 trails state-of-the-art ensembles that use richer engineered features. This work optimizes the systems substrate rather than the predictive model itself. Cross-vendor evaluation is also limited to a single AMD SKU, and the energy figures are steady-state averages from NVML/ROCm-SMI sampling.
Part of an ongoing line of work on portable GPU kernel acceleration for biological and medical AI, benchmarked across NVIDIA H100 and AMD MI300X. See more on the research page.