written once
CPU/GPU baselines
NVIDIA + AMD
bitwise-equivalent
Core bioinformatics workloads (sequence alignment, k-mer indexing, quality control) are still bottlenecked on CPU tools like BioPython, samtools, and Jellyfish, and the GPU solutions that do exist are CUDA-only and locked to a single vendor. That leaves AMD users falling back to the CPU. BioTriton is a library of 20+ Triton GPU kernels that delivers 10–19,000× speedups over CPU and GPU baselines while staying portable: one Triton source compiles to both NVIDIA PTX and AMD ROCm with no modification.
The key insight is that bioinformatics maps naturally onto Triton's block-structured programming model. Its data structures (2-bit DNA encoding, 5-bit amino acids, shared-memory-resident scoring matrices) and algorithms (wavefront-parallel dynamic programming) line up with how Triton wants to express work, which enables domain-aware kernel fusion and memory-hierarchy optimization without vendor lock-in.
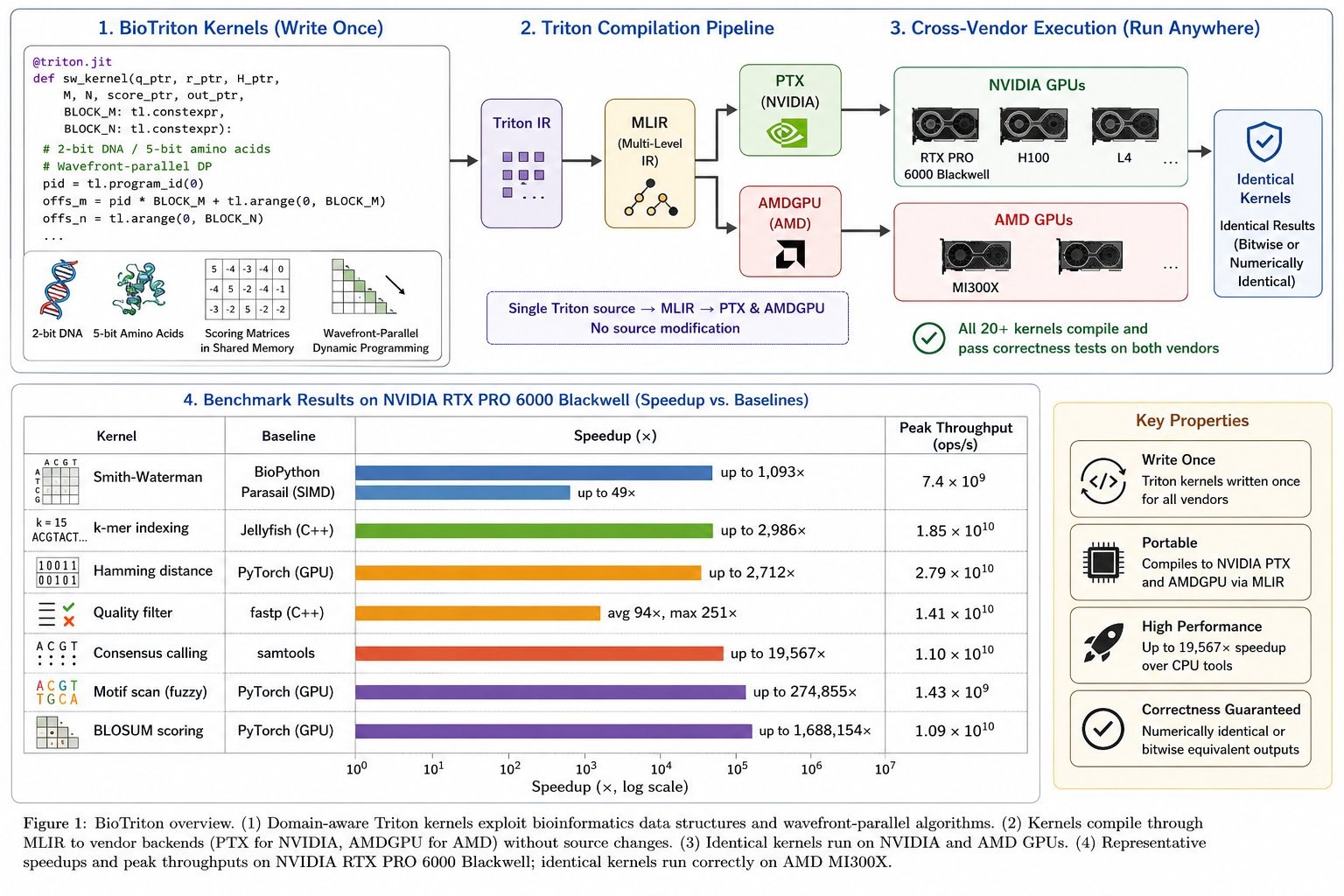
Write once, run on both vendors
BioTriton kernels are written once and compile through MLIR to PTX (NVIDIA) and AMDGPU (AMD) with no source modification. Benchmarked on NVIDIA RTX PRO 6000 Blackwell, H100, L4, and AMD MI300X, all 20+ kernels compile and pass correctness tests on both vendors. That closes a real gap: existing GPU bioinformatics tools like NVBIO and GASAL2 are CUDA-only, forcing AMD users back onto CPU fallbacks.
Benchmark results
Representative speedups on NVIDIA RTX PRO 6000 Blackwell against standard CPU and GPU baselines. Every kernel produces numerically identical outputs (alignment, scoring) or bitwise-equivalent results (quality control, translation), and the identical kernels run on AMD MI300X without recompilation.
| Kernel | Baseline | Speedup | Peak throughput |
|---|---|---|---|
| BLOSUM scoring | PyTorch (GPU) | up to 1,688,154× | 1.09 × 10¹⁰ ops/s |
| Motif scan (fuzzy) | PyTorch (GPU) | up to 274,855× | 1.43 × 10⁹ ops/s |
| Consensus calling | samtools | up to 19,567× | 1.10 × 10¹⁰ ops/s |
| k-mer indexing | Jellyfish (C++) | up to 2,986× | 1.85 × 10¹⁰ ops/s |
| Hamming distance | PyTorch (GPU) | up to 2,712× | 2.79 × 10¹⁰ ops/s |
| Smith-Waterman | BioPython / Parasail | up to 1,093× / 49× | 7.4 × 10⁹ ops/s |
| Quality filter | fastp (C++) | avg 94×, max 251× | 1.41 × 10¹⁰ ops/s |
The speedups against compiled C++ tools (Jellyfish, fastp, samtools) matter most: they show the gains hold against highly optimized native baselines, not just Python reference implementations.
Why it matters
BioTriton shows that Triton is production-ready for portable scientific GPU computing. By targeting MLIR rather than a vendor-specific backend, it gets write-once, run-anywhere portability without sacrificing performance, which is exactly what HPC centers running heterogeneous clusters need: DOE's Frontier and El Capitan use AMD, while most academic clusters run NVIDIA. Future directions include cross-architecture roofline analysis quantifying memory-vs-compute bottlenecks on each vendor, multi-GPU scaling for whole-genome alignment, and BioKernelBench, a reproducible cross-vendor benchmark suite for bioinformatics kernels.
The thesis in one line: bioinformatics data structures and algorithms map cleanly onto Triton's block model, so a single write-once kernel library can hit 10–19,000× speedups and run identically across NVIDIA and AMD, with no CUDA lock-in.
Part of an ongoing line of work on portable GPU kernel acceleration for biological and medical AI, benchmarked across NVIDIA H100 and AMD MI300X. See more on the research page.