These are my personal notes on Flash Attention based on Umar jamil Video. The goal is to build intuition from the memory bottleneck up, through safe softmax, online softmax, block matrix multiplication, and finally the full Flash Attention algorithm.
1. Why Flash Attention?
Standard attention
The standard attention mechanism is:
S = Q · K^T
P = softmax(S)
Output = P · VThe naive algorithm does this in three sequential HBM passes:
- Load Q, K from HBM → compute S = Q·KT → write S to HBM
- Read S from HBM → compute P = softmax(S) → write P to HBM
- Load P, V from HBM → compute O = P·V → write O to HBM

The problem: a memory bottleneck
HBM (High Bandwidth Memory), also called global memory, is the largest but slowest tier. An H100 has 40 GB of HBM at ~1.5 TB/s. By contrast, on-chip shared memory is ~20 MB but runs at ~19 TB/s. Every time we write an intermediate (S, P) to HBM and read it back, we burn roughly 12× slower I/O than if we had kept the data on-chip.
This makes naive attention memory-bound, not compute-bound. The GPU's FLOP capacity sits idle, waiting on data.
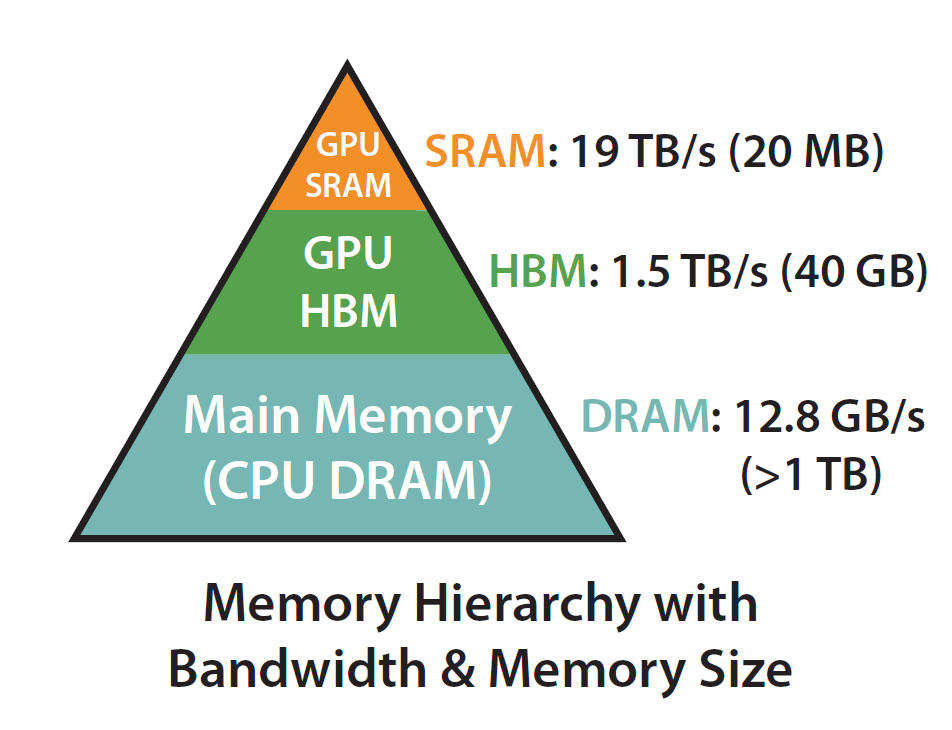
The solution
Keep all intermediates in shared memory by fusing the three passes into one. This requires tiling: divide Q, K, V into blocks small enough to fit on-chip, and incrementally compute the output without ever materializing the full S or P matrices in HBM.
2. Safe softmax
Before tiling, we need numerically stable softmax. The standard definition:
softmax(x_i) = exp(x_i) / Σ_j exp(x_j)Problem: numerical overflow
If any xi is large (say 100), exp(100) overflows float32 (max ~3.4×1038). The fix is to subtract the row maximum before exponentiating:
softmax(x_i) = exp(x_i - m) / Σ_j exp(x_j - m) where m = max(x)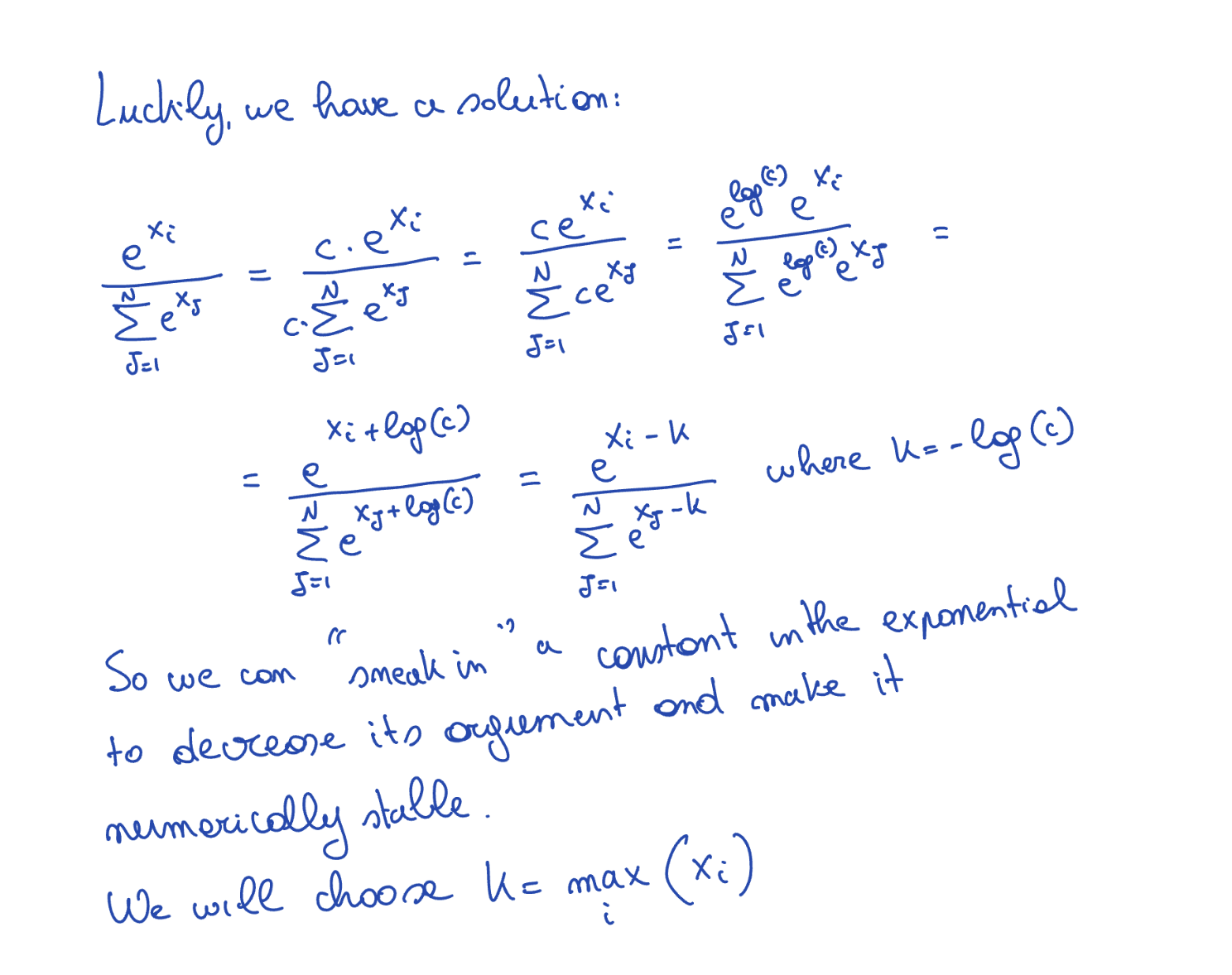
When m = max(x), the largest exponent is exp(0) = 1, and all others fall in (0, 1), well within float32 range.
Complexity
- Find max → O(N) time, O(1) space
- Compute normalization factor L → O(N)
- Apply division → O(N)

For x = [3, 2, 5] with m = 5:
L = exp(3−5) + exp(2−5) + exp(5−5) = exp(−2) + exp(−3) + 1
x_1 = exp(3−5)/L, x_2 = exp(2−5)/L, x_3 = exp(5−5)/LSafe softmax still requires 3 sequential passes over the data. For a sequence of length N, softmax of the N×N attention matrix loads each element 3 times. Can we do it in one pass?
3. Online softmax
Online softmax fuses the max-finding pass and the normalization pass into a single loop, updating a running correction factor as the global maximum increases.
Naive two-pass pseudocode
m_0 = -inf
for i = 1 to N:
m_i = max(m_{i-1}, x_i) # pass 1: find max
l_0 = 0
for j = 1 to N:
l_j = l_{j-1} + exp(x_j - m_n) # pass 2: normalization factor
for k = 1 to N:
x_k = exp(x_k - m_n) / l_n # pass 3: apply softmaxThe key insight: a correction factor
When we discover a new maximum m_new > m_old, we rescale the running sum L to reflect the updated baseline:
L_new = L_old * exp(m_old - m_new) + exp(x_new - m_new)For x = [3, 2, 5, 1]:
- i=1: m=3, l = exp(0)
- i=2: m=3, l = l + exp(2−3)
- i=3: new max m=5, l = l · exp(3−5) + exp(0) ← correction applied
- i=4: m=5, l = l + exp(1−5)
Verifying that the correction is exact:
l_3 = (exp(3-3) + exp(2-3)) · exp(3-5) + exp(5-5)
= exp(3-3+3-5) + exp(2-3+3-5) + exp(5-5)
= exp(3-5) + exp(2-5) + exp(5-5) ✓ (same as if max=5 all along)One-pass pseudocode
m_0 = -inf
l_0 = 0
for i = 1 to N:
m_i = max(m_{i-1}, x_i)
l_i = l_{i-1} * exp(m_{i-1} - m_i) + exp(x_i - m_i)
for k = 1 to N:
x_k = exp(x_k - m_n) / l_n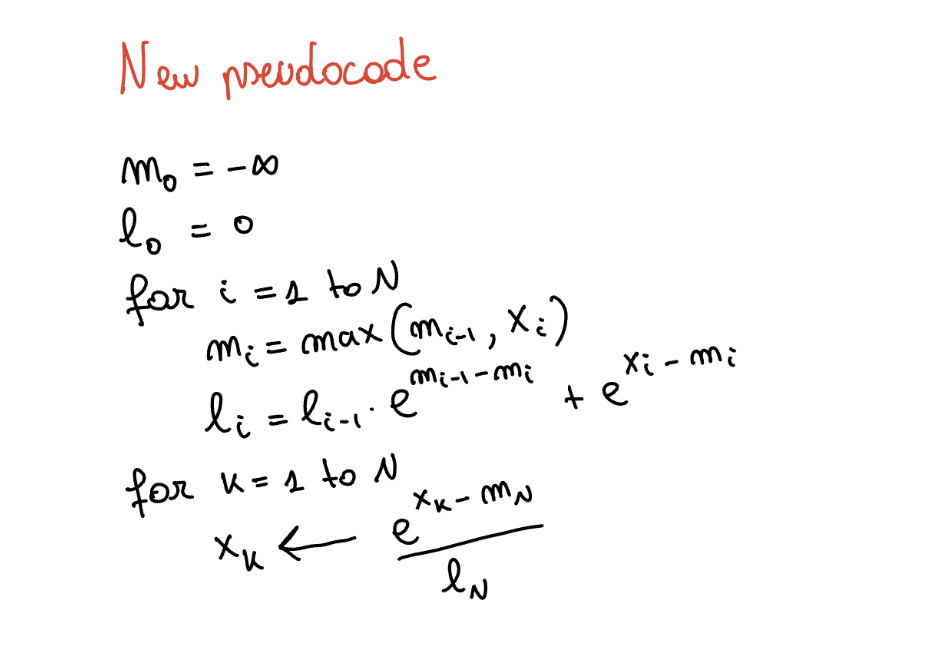
Formal proof that the output matches standard softmax: Online Softmax notes (PDF).
4. Block matrix multiplication
Motivation
For attention we want O = softmax(Q·KT) · V. Even ignoring softmax, naively computing Q·KT materializes an N×N matrix. For N=8192 that's 256M floats = 512 MB in fp16, far larger than shared memory. Block matrix multiplication lets us tile the computation so each tile fits on-chip.
Block structure
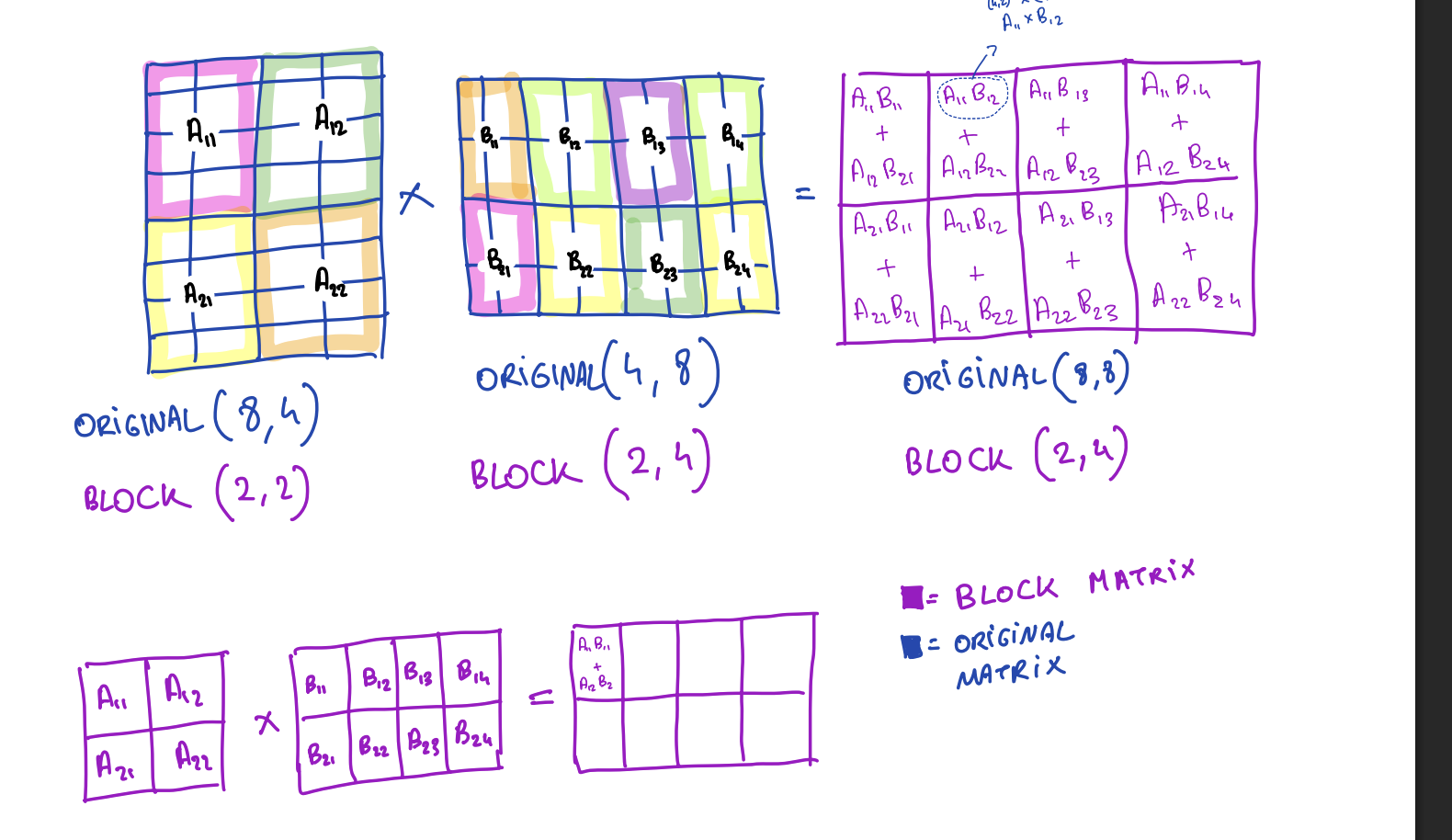
For two 4×4 matrices A, B partitioned into 2×2 blocks:
A = [ A11 A12 ] B = [ B11 B12 ]
[ A21 A22 ] [ B21 B22 ]
C = A × B gives:
C11 = A11·B11 + A12·B21
C12 = A11·B12 + A12·B22
C21 = A21·B11 + A22·B21
C22 = A21·B12 + A22·B22Each block Cij is computed independently from its contributing A and B tiles, exactly what we need to stream through shared memory.
Tiled attention without softmax
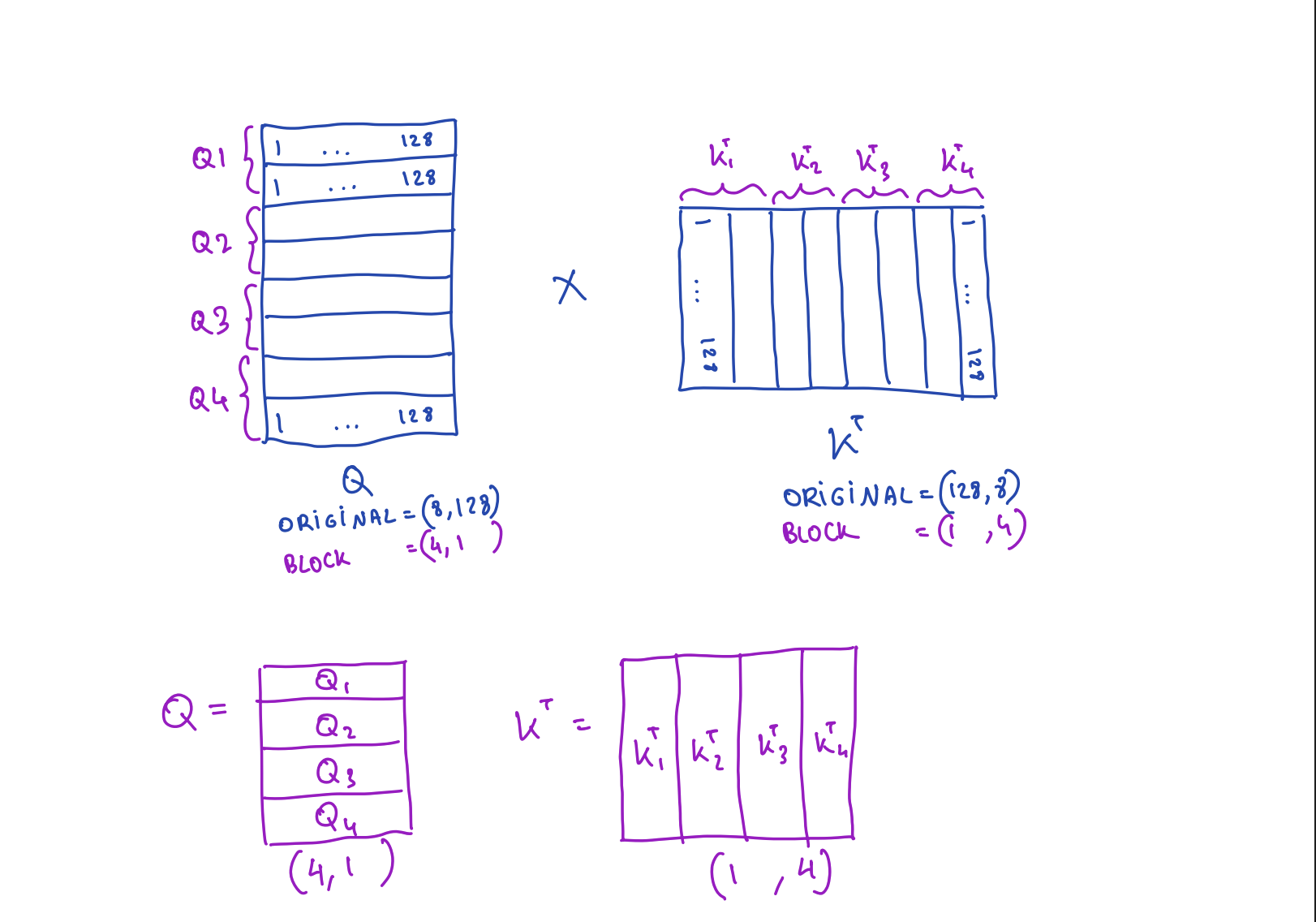
Take Q, K, V each of shape (8, 128), with tile size (2, 128):
Q, K, V shapes: (8, 128)
Block shape: (2, 128) → 4 row-tiles each
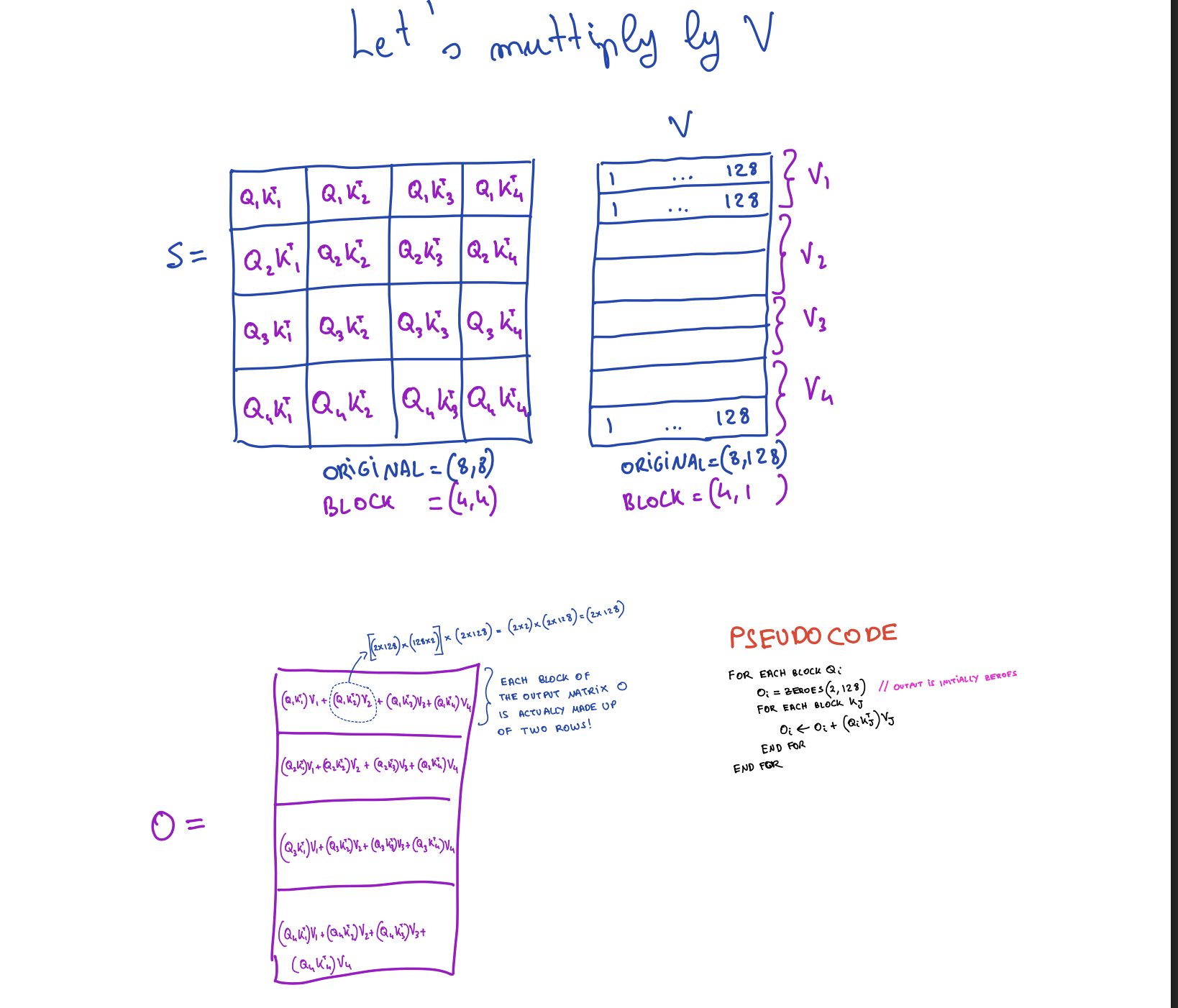
Tiled O = (Q · K^T) · V:
for each Q_i (shape 2×128):
O_i = zeros(2, 128)
for each K_j (shape 2×128):
S_ij = Q_i · K_j^T # (2,128)×(128,2) = (2,2) — fits in SRAM!
O_i += S_ij · V_j # (2,2)×(2,128) = (2,128) — accumulate
end for
end for

5. Applying softmax to block matrices
Now we put softmax back in. The problem: softmax of row i of S requires the global max of that entire row, but when processing tile Sij we only see a partial row.
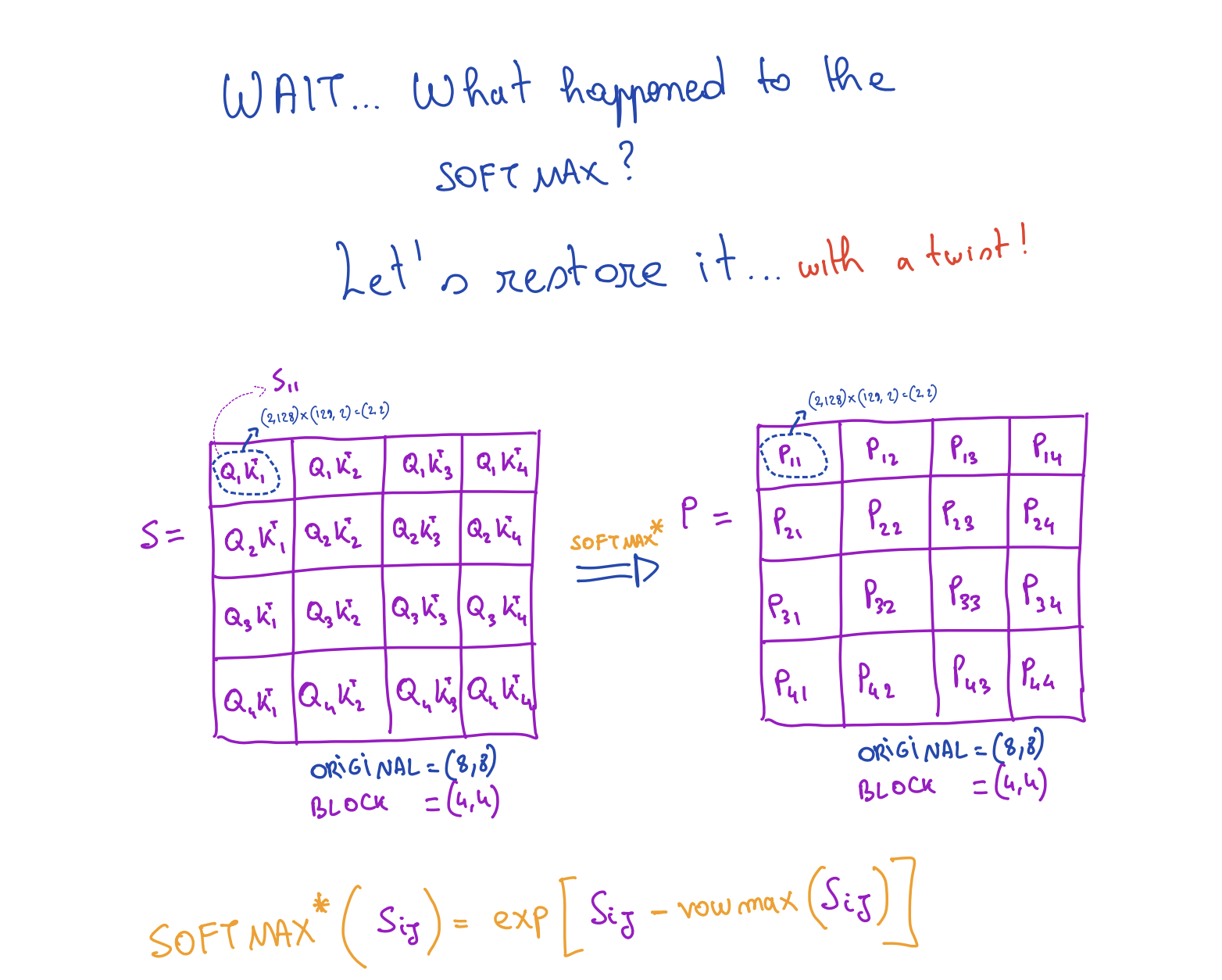
The problem: local vs. global max
When we compute Pij = softmax(Sij) independently per tile, we normalize by the local block max, not the global row max. The resulting Pij are wrong.
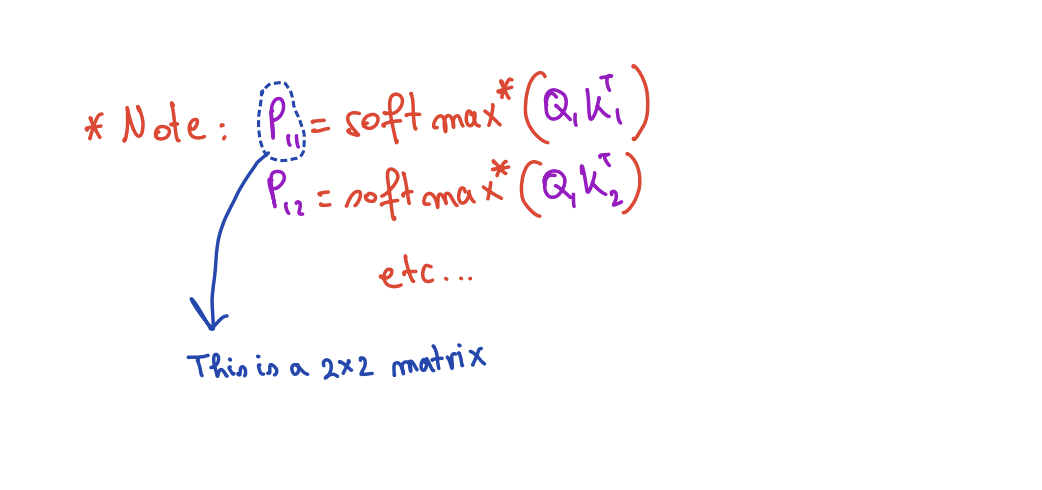
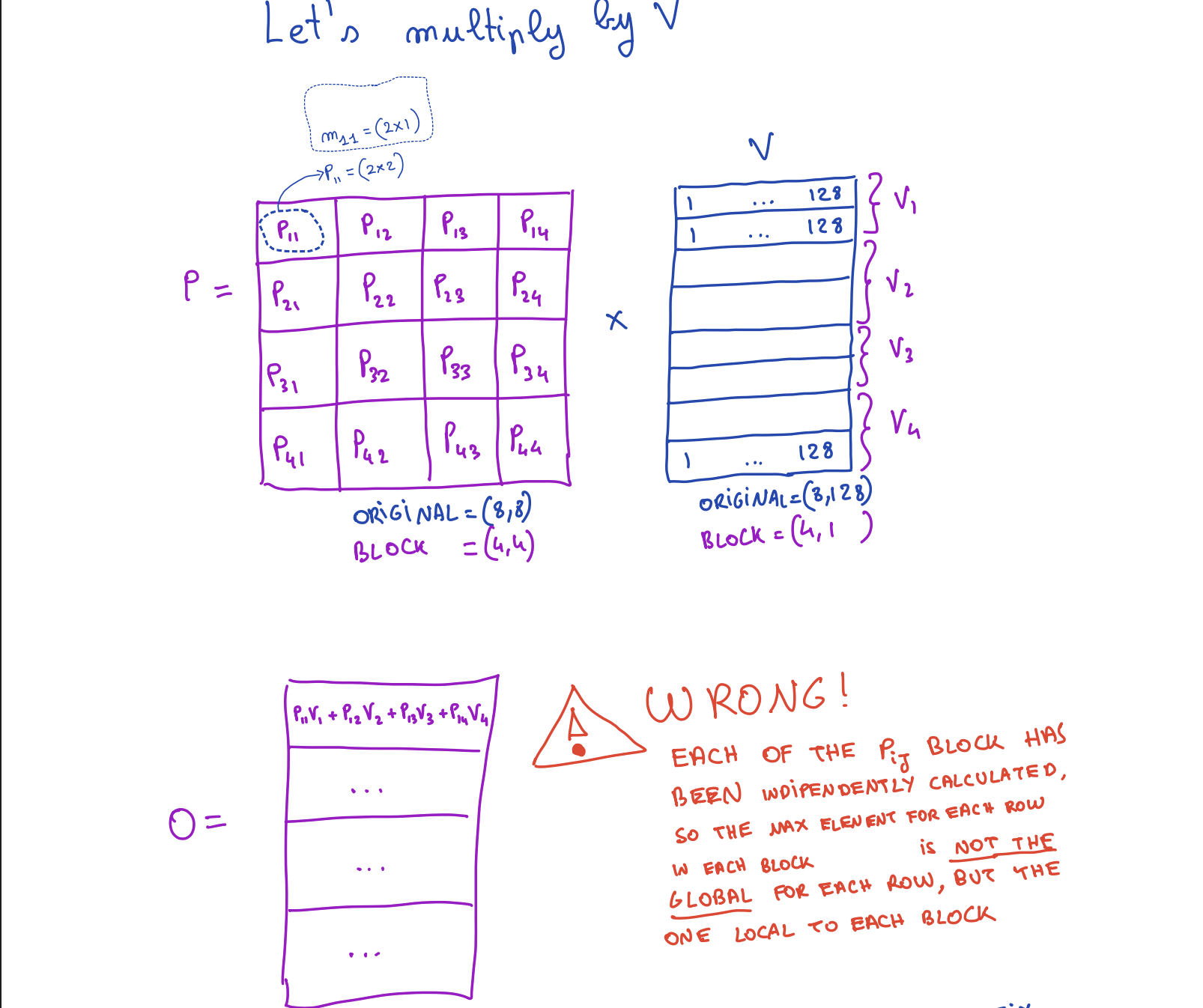
Solution: online softmax correction
We apply the same correction-factor trick from section 3. Maintain running statistics (m, l, O) and rescale the accumulated output whenever the max increases:

For block size (2, 128), processing 2 queries per iteration, the update rule per tile j is:
m_new = max(m_old, local_max(S_j))
l_new = l_old * exp(m_old - m_new) + sum(exp(S_j - m_new))
O_j = diag(exp(m_old - m_new))^{-1} · O_{j-1} + P_j · V_j
where P_j = exp(S_j - m_new)At the end: O_final = O_last / l_last, applying the normalization denominator once.
Flash Attention 2 forward pass

The complete algorithm processes Q in tiles (outer loop), and for each Q tile streams over all K/V tiles (inner loop). The entire computation happens in SRAM. S and P are never materialized in HBM. This is what gives Flash Attention its ~3–4× memory bandwidth reduction and enables much longer sequences at the same memory budget.
Found this useful? Connect on LinkedIn or see related work on GitHub.